ORNL Titan architecture
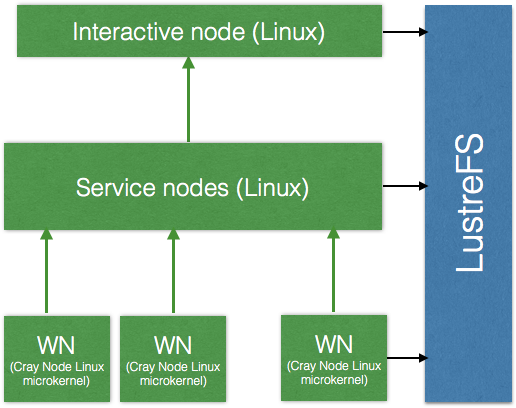
On ORNL Titan users can access only the interactive nodes (IN) and LustreFS via a SSH. There is no access to Service Nodes which do the preparations for PBS jobs. Worker nodes (WN) run Cray Linux microkernel and have neither inbound neither outbound network connectivity. WN arre interconnected by InfiniBand network.
The communication between INs and WNs is only possible through a shared filesystem - LustreFS.
To access ORNL Titan one needs an RSA token obtained from ORNL.
Titan/ALICE services interaction
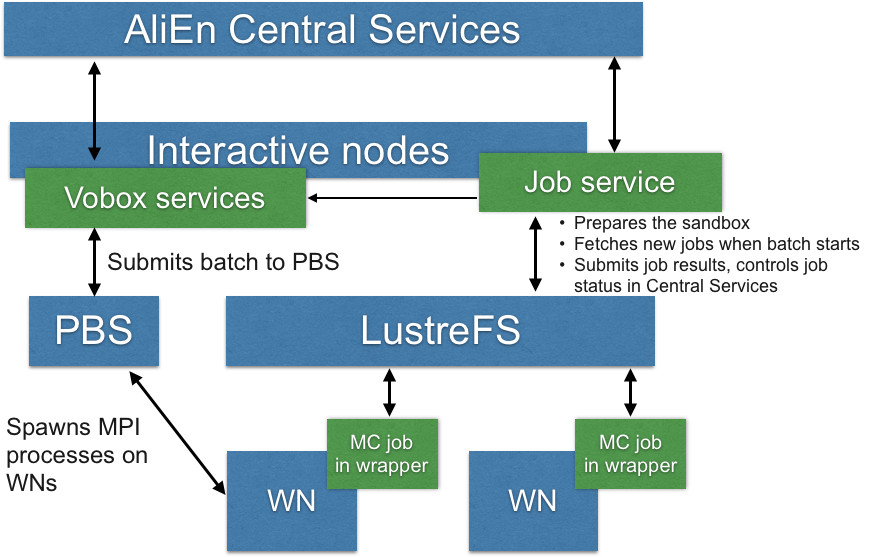
As there is no network connectivity on WNs there is a JobService that identifies that batch is ready to accept new jobs, takes jobs from AliEn Central Queue, transmits their heartbeats to monitoring services, upload job results after job has completed and marks the job as DONE/ERROR_* .
Computing time on ORNL Titan is received through PBS interface.
A simple example for PBS script on Titan:
#!/bin/bash
# Begin PBS directives
#PBS -A CSC108
#PBS -N sleep_test
#PBS -j oe
#PBS -l walltime=00:20:00,nodes=1
#PBS -l gres=atlas1
# End PBS directives and begin shell commands
cd $MEMBERWORK/csc108
module load cray-mpich/7.2.5
module load python/3.4.3
module load python_mpi4py/1.3.1
aprun -n 1 ./get_rank_and_exec_job.py
The actual implementation for ALICE workflow batch implementation is in Titan.pm module, the module submits it through a regular qsub interface (no stdin inputs are allowed on Titan, thus the module utilizes "qsub <filename>" command).
ALICE PBS batch life cycle on Titan
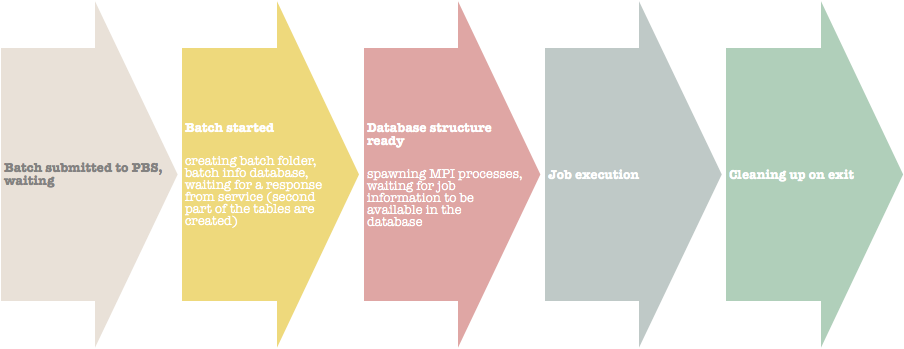
After ALICE batch is submitted it spends some time in the common PBS queue.
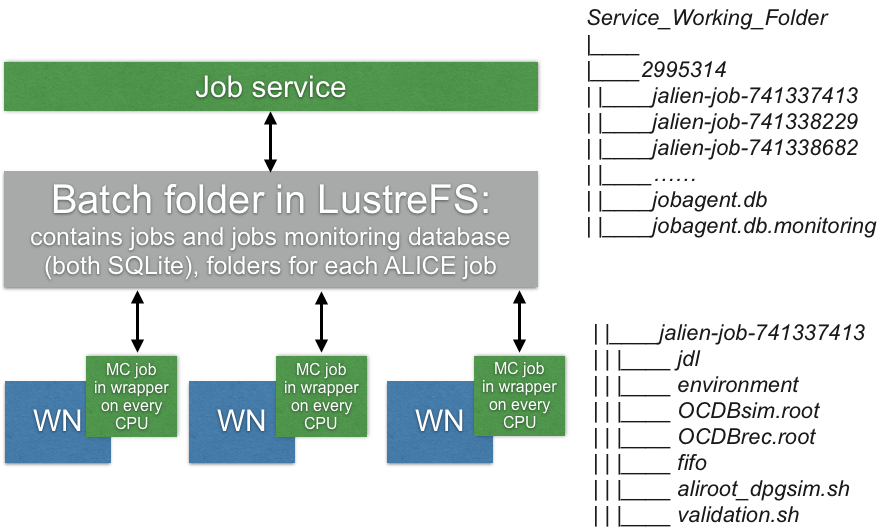
After it is started it creates its working folder (inside of a working folder for a JobService) and SQLite database (jobagent.db) inside ofit that contains batch info (jobagent_info) and waits for a response from JobService that operates with this working folder. The service responds with its own part of the database structure: a table (alien_jobs) which describes jobs assigned to processes in this batch (every process is identified by its own MPI rank within this batch) and another SQLite database for storing job heartbeats (jobagent.db.monitoring).
See descriptions for the databases below.
When there are MPI processes in the batch that do not run any ALICE jobs the service fetches jobs from Central Queue, downloads all of the files and assigns job information to an available process.
The general idea describing folder hierarchy and folder contents is the following:
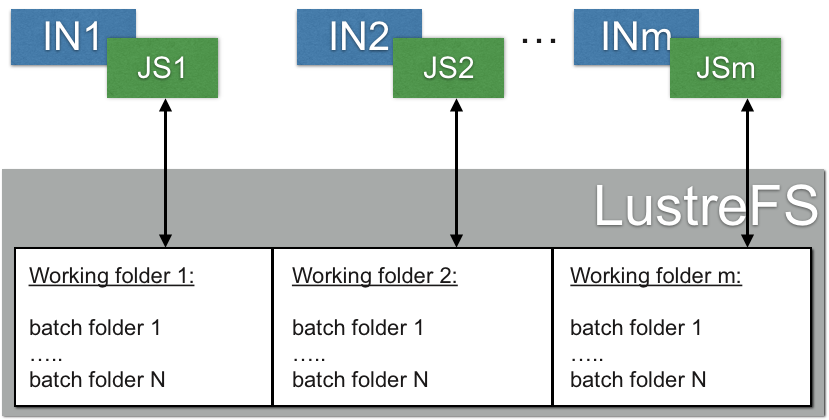
If single JobService is using too mush resources on an interactive node - this approach can be scaled for many interactive nodes. VOBox CE module can use multiple working folders each operated by its own JobService on LustreFS. The working folder for a new PBS batch can be selected, for example, using a simple round robin policy.
Working folder is selected by Vobox CE service before batch submission (for example, using a simple round-robin)
SQLite databases structure
The latest database structure is the following.
jobagent.db: contains general information about batch and running jobs.
>> .schema
CREATE TABLE jobagent_info (ttl INT NOT NULL, cores INT NOT NULL, started INT, max_wait_retries INT);
CREATE TABLE alien_jobs (rank INTEGER NOT NULL,
queue_id VARCHAR(20),
user VARCHAR(20),
masterjob_id VARCHAR(20),
job_folder VARCHAR(256) NOT NULL,
status CHAR(1),
executable VARCHAR(256),
validation VARCHAR(256),
environment TEXT,
exec_code INTEGER DEFAULT -1, val_code INTEGER DEFAULT -1);
jobagent.db.monitoring: contains a table for job heartbeats information.
>> .schema
CREATE TABLE alien_jobs_monitoring (queue_id VARCHAR(20), resources VARCHAR(100));
Vobox start
AliEn is installed locally in /ccs/home/psvirin/alien/bin .
To start VoBox do the following steps:
export PATH=$PATH:/lustre/atlas/proj-shared/csc108/psvirin/alice.cern.ch/alice.cern.ch/bin/
cd /ccs/home/psvirin/alien/bin
./alien proxy-init -valid 120:00
./alien StartMonitor
./alien StartMonaLisa
./alien StartCE
There must be a Titan.pm module for Vobox CE service in /autofs/nccs-svm1_home1/psvirin/alien.v2-19.346/lib/perl5/site_perl/5.10.1/AliEn/LQ/Titan.pm
CVMFS on Titan
CVMFS on Titan is located at /lustre/atlas/proj-shared/csc108/psvirin/alice.cern.ch/alice.cern.ch
It is not a real CVMFS but its snapshot which is updated by publisher script running on dtn04.ccs.ornl.gov hourly.
ALICE job wrappers
Located in /lustre/atlas/proj-shared/csc108/psvirin/ALICE_TITAN_SCRIPTS/ .
ls /lustre/atlas/proj-shared/csc108/psvirin/ALICE_TITAN_SCRIPTS/
alien_multijob_run.sh get_rank_and_exec_job.py
get_rank_and_exec_job.py is used by Titan.pm module. This script is spawned by MPI, it takes its rank, then executes alien_multijob_run.sh which actually communicates with job service through SQLite databases, executes the payload and pushes job heartbeats into SQLite table. In other words, it is a simple networkless reimplementation of AliEn JobAgent's corresponding parts.
TitanJobService compilation
TitanJobService repository is currently located in the separate git branch:
git checkout Titan
Running compilation:
export PATH=/lustre/atlas/proj-shared/csc108/psvirin/jre1.8.0_74/bin/:$PATH
cd /lustre/atlas/proj-shared/csc108/psvirin/jalien-latest-ja/jalien
./compile.sh
Running TitanJobService
Environment variables to be set:
export installationMethod=CVMFS
export site=ORNL
export CE=ALICE::ORNL::Titan
export WORKDIR=/lustre/atlas/scratch/psvirin/csc108/workdir2 # or a path to a folder where PBS batches will create their folders
export TTL=36000 #(optional/unused currently)
export cerequirements='other.user=="psvirin"' # (optional)
Path variables:
Job Service uses alternate JDK8 (it has some security extensions installed)
export PATH=/lustre/atlas/proj-shared/csc108/psvirin/jre1.8.0_74/bin/:$PATH
# adding path to alienv
export PATH=$PATH:/lustre/atlas/proj-shared/csc108/psvirin/alice.cern.ch/alice.cern.ch/bin/
Running job service:
You should have your Grid credentials located at ~/.globus/
(enter your Grid certificate password as jAliEn not supporting non-password certificates or X509 proxy certificates for the current time)
Service can be started on any of Titan interactive nodes (e.g., titan-ext3.ccs.ornl.gov, dtn04.ccs.ornl.gov, etc.)